Document Read Agent
Document Read Agent uses a large language model (LLM) to extract information from documents and outputs the results to files in the working folder. The GPT model analyzes text data in PDF files using text analysis, while the Gemini model treats all data in PDF files as images for analysis. If you're unfamiliar with how to prompt the language model to achieve task goals, use "Ask EMILY" to let the AI generate model-friendly goal prompts.
Parameters
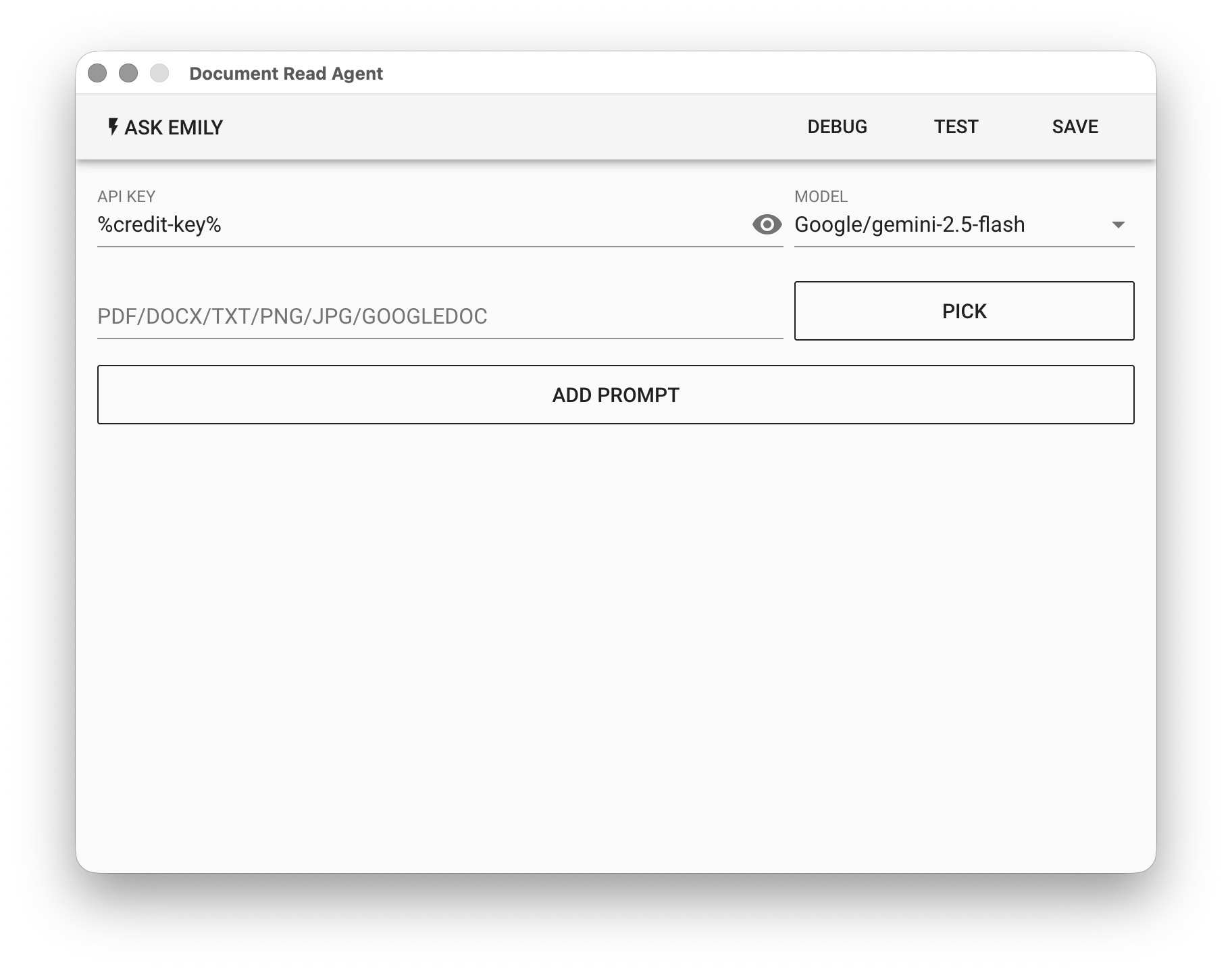
API KEY - OpenAI or Google API key. Supports the %FILENAME% variable, or use the prepaid dedicated key %credit-key%.
- For OpenAI API Key, refer to Apply for OpenAI Key
- For Google API Key, refer to Apply for Gemini Key
MODEL - Currently supported models:
| Platform | Models | Pricing |
|---|---|---|
| OpenAI | gtp-5, gpt-5-mini, gpt-4.1, gpt-4.1-mini | OpenAI Website |
| gemini-3-pro, gemini-3-flash, gemini-2.5-pro, gemini-2.5-flash | Gemini Website | |
| Anthropic | claude-opus-4-6, claude-sonnet-4-6, claude-haiku-4-5 | Anthropic Website |
PDF/DOCX/TXT/PNG/JPG/GOOGLEDOC - Input document file. Click "PICK" to select a file, or use the %FILENAME% variable. In addition to the listed document formats, Google Docs ID is also supported.
ADD PROMPT
Add a natural language prompt to tell the model what information to extract from the document. FILENAME specifies the file to write to in the working folder. PROMPT tells the model what information to extract from the document.
Example
Using TSMC's financial report as an example, the goal is to extract the revenue for Q1 of year 2025.
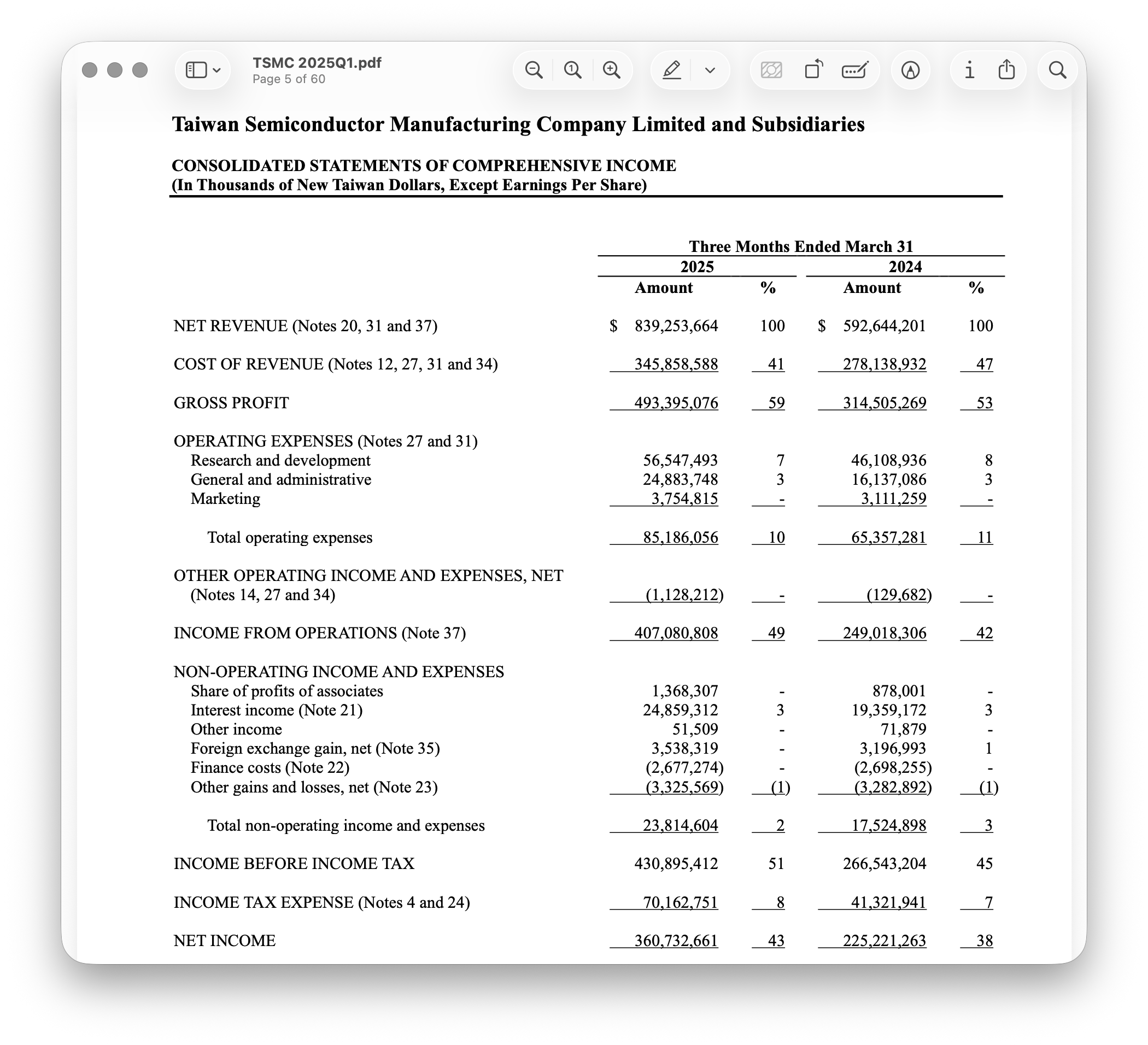
For the Document Read Agent, select the model Google/gemini-2.5-flash and add a prompt with filename TSMC_2025Q1_Revenue and content: Extract the total revenue for TSMC in the first quarter of 2025(Q1 2025).
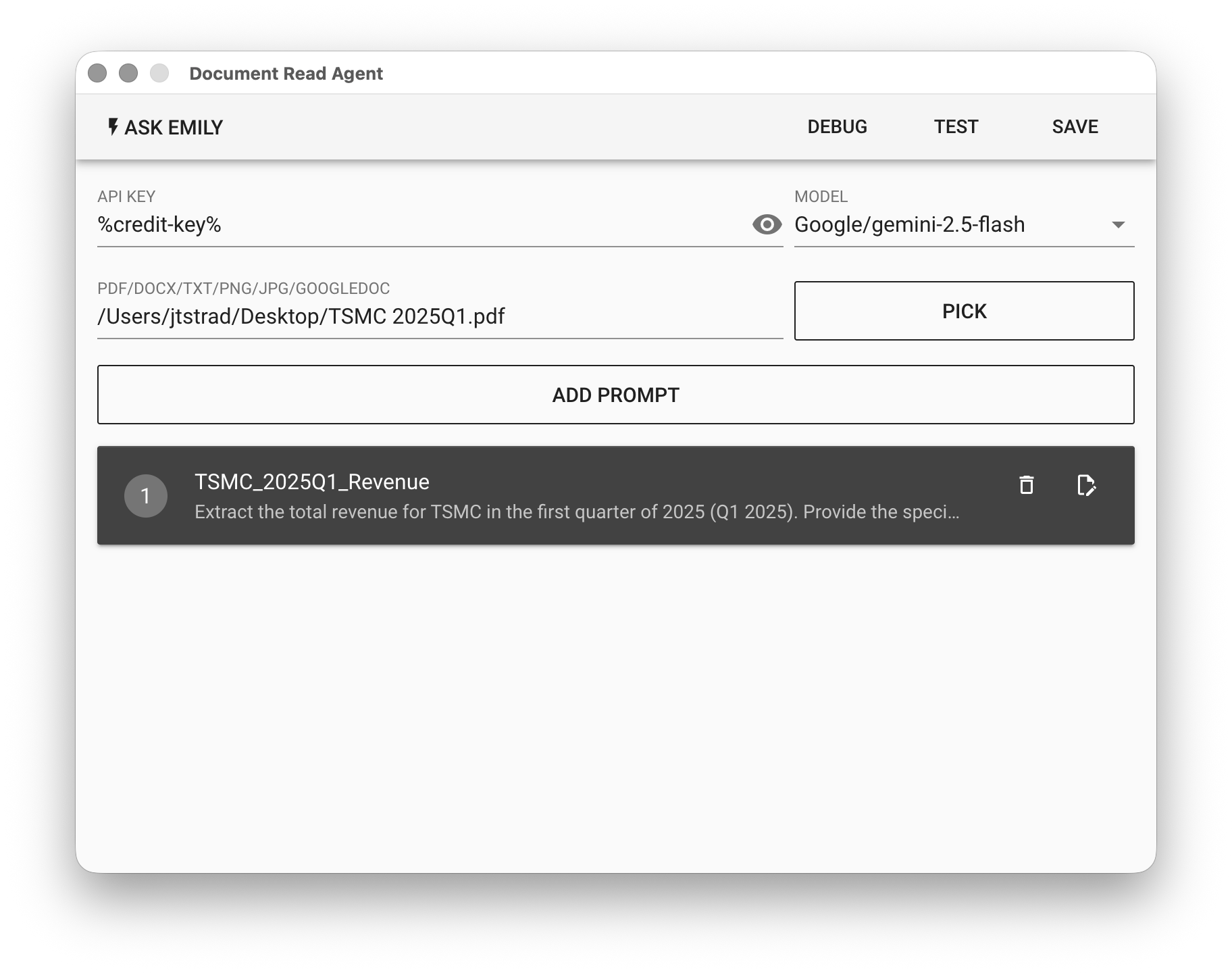
Finally, click "TEST" to try it out, then check whether the content of TSMC_2025Q1_Revenue.txt in the working folder is correct.